Met to discuss the next steps.
Pádraig described a method for testing the quality of a community (i.e. whether it has been partitioned correctly), by means of an infinite(?) random walk, described in a notation based on Huffman(?) numbers. The length of the decriptions between communities determines the quality of the partitioning. In that a random walk should spend much more time in an actual community, as there are few links out of it. He related this to BUBBLE rap, in that it might be important to test the quality of the communities used in the algorithm, to test how good the community finding algorithm is (e.g. if done on the fly).
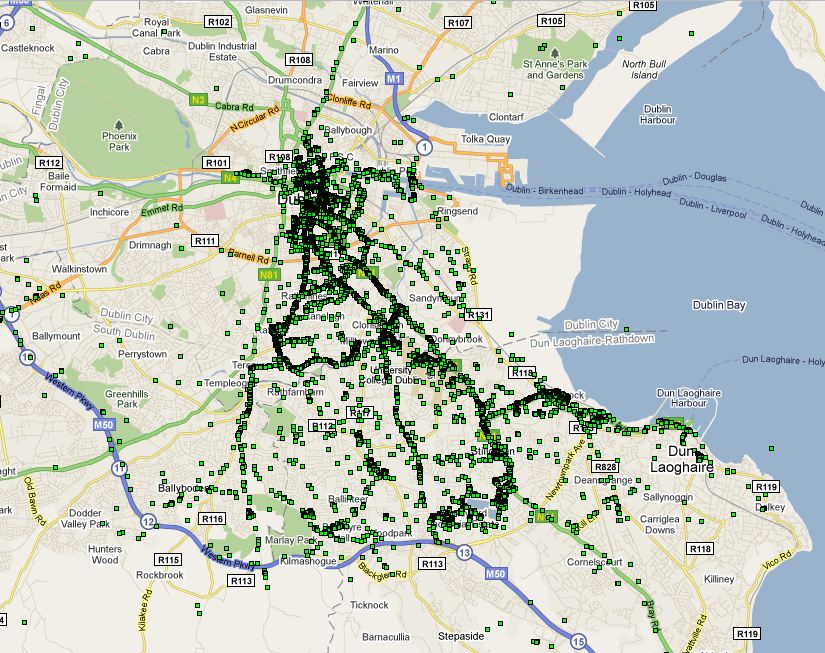
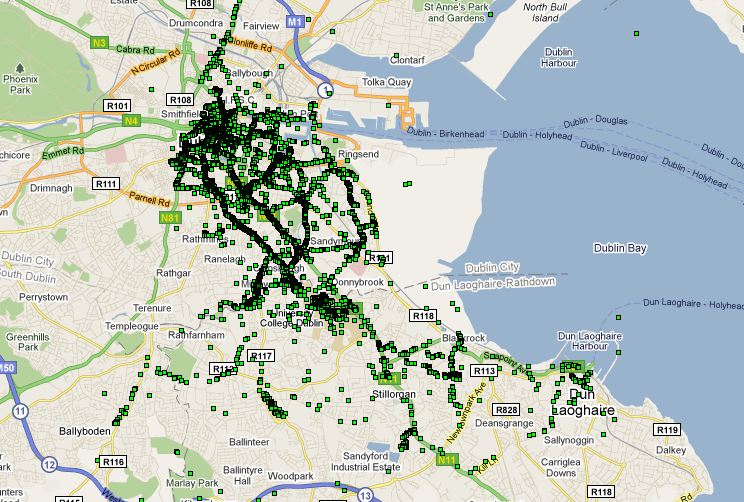
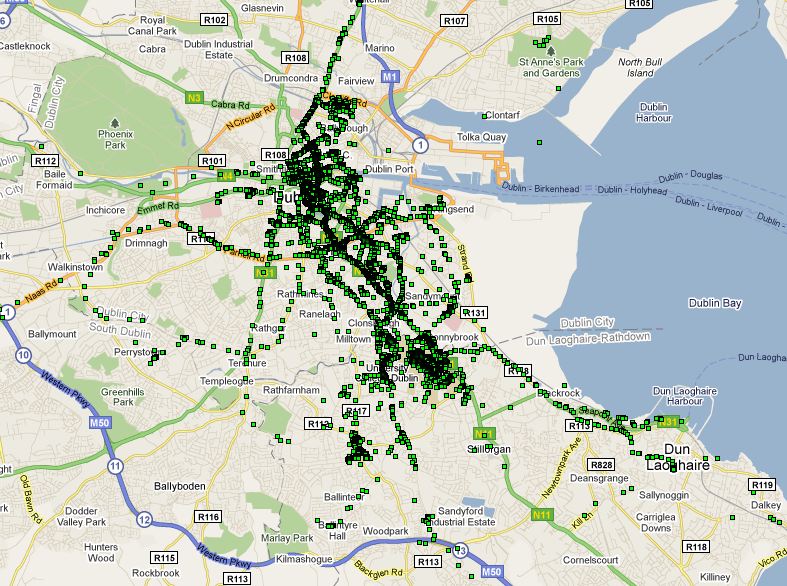
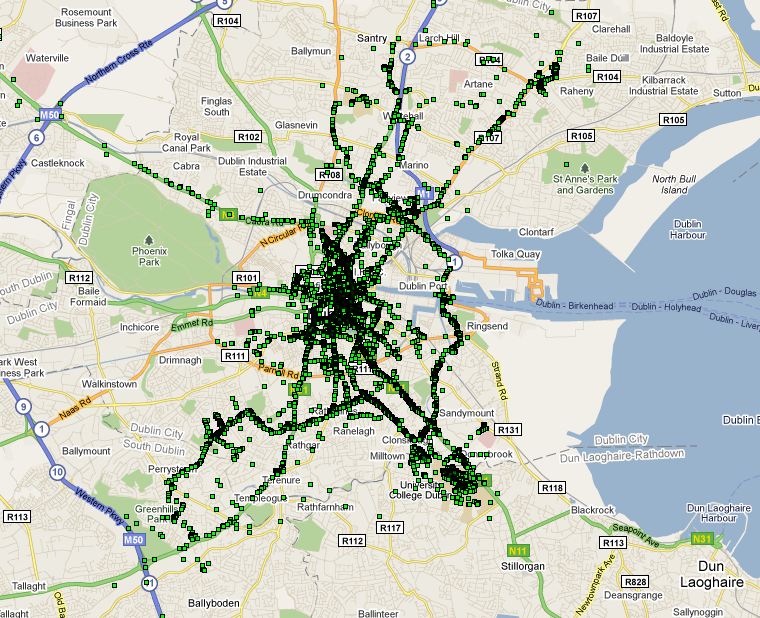
We also spent some time discussing how to define a place, from a series of location readings. Firstly we need to consider whether we determine a location in terms of an individual node, or the global set of readings. After some discussion we decided for the purposes of this simulation, we will determine it globally. This will at least give us an idea about what the data looks like. If it turns out that this seems to produce ‘places’ that encompass too wide an area, we should consider revising this decision.
Sec0ndly, we need to find the means of partitioning the space. We discussed last week clustering the readings using a k-Clique algorithm. I contacted Derek Greene, who supplied me with some links and advice about achieving this. It was his feeling that it was more a distance-based clustering problem, with weighted links, rather than an unweighted k-Clique algorithm (I have yet to explore this), and suggested I initially explore the data using something like MultiDimensional Scaling (MDS), and suggested a Java based implementation.

Davide suggested another approach to the partitioning of locations, in the form of a grid based approach, splitting the landscape based on latitude/longitude, and a size dimension,effectively making a grid of the planet, where all nodes implicitly know that a lat/long is part of a location, if it falls within a grid sqaure.
These two methods have their benefits, the first being that we can get a really good idea about locations based on the data we have, without the worry of partitioning the same place into two locations, in a fairly straightforward way, the second being that all nodes could calculate all possible locations and refer to them when neccassary. We decided in the end to use a clustering algorithm.
I talked through my initial analyis of the Social Sensing Study data, and described how I had found hints of a Bluetooth collection problem, in that for most devices, they had a very low number of instances of device readings. i.e. there were very few occasions when they actually detected Bluetooth devices. This means that using this dataset for detecting proximity using Bluetooth alone may not be very realistic.
| Entity |
WiFi |
% |
BT |
% |
Location |
% |
| 1 |
10545 |
12 |
2416 |
3 |
10905 |
12 |
| 2 |
70724 |
79 |
18980 |
21 |
74522 |
83 |
| 3 |
55242 |
62 |
10303 |
12 |
72661 |
81 |
| 4 |
20624 |
23 |
2496 |
3 |
22760 |
25 |
| 5 |
27171 |
30 |
5745 |
6 |
29265 |
33 |
| 6 |
62719 |
70 |
6251 |
7 |
66243 |
74 |
| 7 |
37571 |
42 |
5916 |
7 |
46798 |
52 |
| 8 |
18284 |
20 |
6081 |
7 |
22155 |
25 |
| 9 |
43976 |
49 |
3406 |
4 |
44720 |
50 |
| 10 |
40316 |
45 |
8976 |
10 |
43216 |
48 |
| 11 |
57190 |
64 |
15957 |
18 |
70937 |
79 |
| 12 |
76976 |
86 |
1542 |
2 |
79010 |
88 |
| 13 |
43285 |
48 |
7706 |
9 |
47767 |
54 |
| 14 |
29630 |
33 |
20801 |
23 |
30127 |
34 |
| 15 |
40417 |
45 |
6665 |
7 |
48979 |
55 |
| 16 |
26864 |
30 |
1088 |
1 |
27693 |
31 |
| 17 |
23075 |
26 |
13154 |
15 |
29570 |
33 |
| 18 |
52615 |
59 |
11070 |
12 |
54305 |
61 |
| 19 |
60182 |
67 |
5251 |
6 |
64364 |
72 |
(for each type of data, the number of readings out of roughly 89280 possible readings – every 30 seconds for 1 month)
I suggested an alternative solution, using WiFi co-location records instead. (see the paper (cite?!!) that used a similar thing in their evaluation). I envisage using the logs of WiFi access points in view to determine whether one device is co-located with another. There are three mechanisms for doing this that I thought about afterwards.
- If two devices can see the same WiFi access point, then they are proximate
- If two decices can see the same WiFi access points, and the one witht the strongest signal is the same, then they are proximate
- If the list of WiFi access points that two devices can see overlaps by at least N, then they are proximate
Davide suggested an algorithm that combines these three, which accounts for situations where two nodes are between two wifi points, close to each other, but the signal strength of the WiFi points would result in not being co-located in situation 2 above. Based in the difference between the signal strength of the top 2 (or extended to top N) access points.

We decided that this was worth investigating further.
We talked about an abstract database structure, into which any dataset of this nature could be placed, so that we can compare different datasets. It was much the same as before.
| Entitity Table |
|
| Entity ID |
|
| Identifier (BT MAC ADDRESS?) |
|
| Name |
|
| Contact Table |
Effectively lists edges between nodes |
| Contact ID |
Instance ID |
| Entity ID |
Source |
| Entity ID |
Destination |
| Contact start time |
|
| Contact end time |
|
| Places Table |
|
| Location ID |
|
| Entity ID |
The entity that knows this location |
| Location Center |
lat/long/alt(?) |
| Location radius |
in meters |
| Location Name |
? |
Pádraig suggested that we will need to think about the on-node data structure at some point soon, but that it will be determined by the way that nodes choose to communicate.
Node A:
Visits Loc: L1, l2, l3, l4
Sees Persons: p1, p2, p3
Node B:
Visits Loc: L7, l2, l1, l9
Sees Persons: p2, p8, p6
However, we decided to concentrate first on getting the places clustered, and getting the proxmity records converted into contact windows/periods.
So for the next meeting I said that I would try to have the clustering algorithm implemented and tested on the dataset, as well as checking the bluetooth records issue, and, assuming the data is missing, using the WiFi mechanism to derive contact windows/periods. I also said I would think about the data-structure for the nodes.